


Even very small, open source LLMs like Mistral-7B achieved the same performance as GPT-4 when given the correct context.
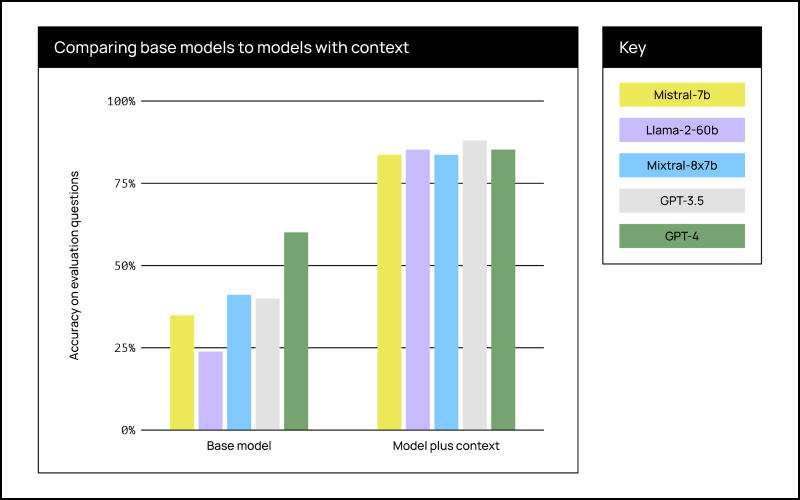
These results surprised us because the study has “real world” challenges we encounter in building solutions for our financial services, healthcare, defense, pharma, and manufacturing clients. The documents contain arcane terminology, complex structure, and we asked human-generated questions. Nevertheless, we found that smaller models achieved the same results when provided the right context.
These results have several implications for enterprise AI strategy:
- Applications built with small, open source LLMs can achieve the same performance while being orders of magnitude faster and less expensive.
- Companies can deploy LLMs within their environment and maintain full control over models and data without sacrificing performance.
- Although massive LLMs demonstrate compelling research breakthroughs, investments in team, infrastructure, and tools have higher ROI.

We initiated this study to answer several key questions we encounter in client projects:
1. Which LLM system design choices are most important?We identified 13 different options for improving LLM application performance in our LLM optimization playbook including model choice, fine-tuning, context, and agents. While much literature is devoted to specific decisions such as fine-tuning, very little is written about choosing among the available options. By systematically removing optimization through ablation, we can test the relative impacts of each.
2. Will open source LLMs perform well on “real world” problems? We’ve built and deployed dozens of enterprise AI applications over the past seven years. Inevitably we find that “real-world” challenges are harder than straightforward textbook examples. Business documents such as policies, contracts, and medical reports all contain important structure and arcane terms that need to be retained and passed to the LLM for context. Additionally, user questions test edge conditions more than questions generated by generative models.

In Episode 17 of our Generative AI Series we demonstrated a LLM Retrieval Augmented Generation (RAG) chat application built on the regulations issued by Formula 1’s governing body, the Fédération Internationale de l'Automobile (FIA). We also gave a demo and provided a detailed technical discussion during a subsequent YouTube live discussion.
The application allows fans to ask detailed questions about the sport’s rules. Figure 2 is a screenshot.
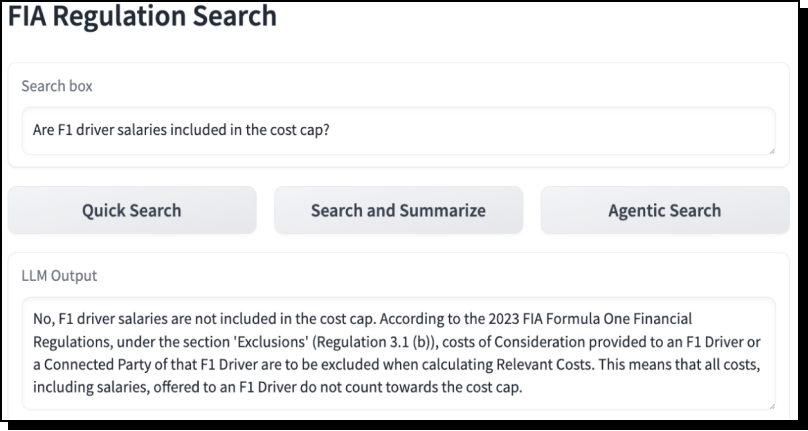
Figure 2. A screenshot of The FIA Regulation Search RAG application answers user questions about the sport’s complex rules.
.png?width=808&height=585&name=Rectangle%201623%20(2).png)
Figure 3. An example of the FIA Formula 1 Financial Regulations containing arcane definitions, complex rules, and complex document structure. These documents are similar to business documents in financial services, health care, and manufacturing.
Complex rules and arcane, business-specific terminology
Business documents such as policies, operating manuals, and physician’s reports contain arcane and business-specific terminology. The FIA regulations have similarly complex language on topics like car construction, financial reporting, and event organization. For example, Figure 3 is an excerpt from the section on calculating costs. The LLM needs access to FIA’s definitions of Marketing Activities, Total Costs, and Relevant Costs to answer user questions.
Complex document structure that requires data cleansing
Business documents also contain both critical structure and extraneous information in columns, sections, subsections, tables, and figures. These documents need to be parsed and cleansed into a format for the LLM. Formula 1 regulations have similar challenges.
For example, Section 3.1 in Figure 2 lists “Excluded Costs”in subsections, (a)-(y). When parsing these subsections we need to retain the context that each is an “Excluded Cost”. The LLM cannot answer questions without this information.
Complex, human-created evaluation questions
Our evaluation questions are manually created based on racing fan questions and crash incident reports. These questions cover complex scenarios and more accurately represent user behavior.
Example question and answer from our evaluation framework:
Human-generated question: Are F1 driver salaries included in the cost cap?
Answer: No, F1 driver salaries are not included in the cost cap. Per Section 3.1(b) of the Formula 1 Financial Regulations, all costs of Consideration provided to an F1 Driver, or to a Connected Party of that F1 Driver, in exchange for that F1 Driver providing the services of an F1 Driver to or for the benefit of the F1 Team, together with all travel and accommodation costs in respect of each F1 Driver, must be excluded from the Relevant Costs when calculating the cost cap.
Other studies use LLMs to automatically generate a large number of evaluation questions. GPT-4 tends to slightly rephrase sections into questions. This approach makes both retrieval and response generation easier, and it results in better performance than can be expected in deployment. See Figure 4 for an example.

Figure 4. Results from asking GPT-4 to generate a question about drivers from section 3.1 of the F1 rules. Notice how it restates the question using similar language as the source material. Generating questions with LLMs makes both retrieval and response generation easier, and it results in better performance than can be expected from user-generated questions.
Study approach and evaluation process
We developed the Formula 1 RAG system through a series of stages:
Stage 0: Just a Base LLM
Stage 1: LLM + Document Search (RAG)
Stage 2: Add More Context
Stage 3: Give the Models Control (Agents)
We describe each stage in detail in the Appendix.
At each stage we measured response accuracy to this set of 25 evaluation questions. Because the LLM-generated responses are non-deterministic, we ask each evaluation question three times and average accuracy over all responses to all questions. We then used GPT-4 to evaluate the RAG-generated responses and manually reviewed them
We tested the following models at each stage:
- OpenAI’s GPT-4
- OpenAI’s GPT-3.5
- Mistral’s 7B Instruct
- Mistral’s Mixtral 8x7B Instruct
- Meta’s Llama2 70B Chat
OpenAI’s models are accessed through their API, while the others are accessed through Perplexity’s API. We use the latest version available of all models.
As discussed above, we initiated this study to answer two key questions:
- Which LLM system design choices are most important?
- Will open source LLMs perform well on “real world” problems?
Figure 5 below summarizes our findings and answers both. Details are in the Appendix.
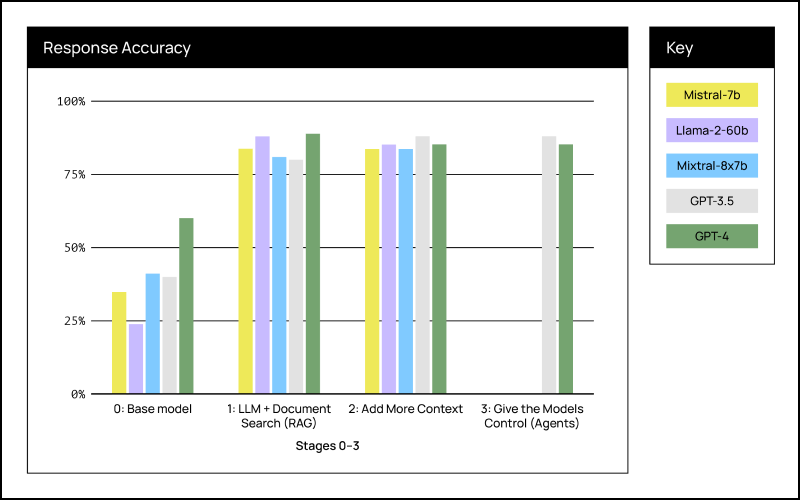
Figure 5. Results of our study. Although powerful base models like GPT-4 perform better “out-of-the-box”, adding context resulted in equivalent performance across all models. Since most business applications require context, small and open source models are a better option.
Not surprisingly, GPT-4 is the best performing model in Stage 0 because it is trained on a larger data set.
The most valuable insight occurs at Stage 1: adding context (RAG) is the most important optimization and makes the choice of model irrelevant. We achieved the same performance between GPT-4 (estimated 1.7 trillion parameters), and a free, open sourced Mistral model (7 billion parameters).
In Stage 2 we see that adding additional context, definitions that help the LLM interpret the regulations, adds slightly more performance and stability.
Including agents did not improve performance in Stage 3. We did not test agents with the open source models due to time constraints, but do not think they would have altered the results on our test set.
This is one small study on a single application with only 25 evaluation questions. Getting good LLM application performance can require many options including agents, fine-tuning, context, and tools that we didn't fully explore.
Nevertheless, these results have strategy implications for CXOs and enterprise analytics leaders. We selected documents and evaluation questions that represent challenges encountered in industries like financial services, health care, manufacturing, defense and retail.
Small and open source models are your best option
Most media attention focuses on the latest, largest, proprietary models that can process the most tokens. While these models demonstrate amazing performance on generic benchmarks, enterprise solutions always include context. When this context is included, smaller and open source models perform well.
Since smaller models are 10-100x less expensive and run 2-5x faster, they are a better choice for most applications.
You can maintain full control over data without sacrificing performance
Many teams cannot send data to third-party APIs like OpenAI, and thus hosting models within their environment is the only option. This constraint is not a barrier to LLM adoption.
If you don’t have GPUs available, data centers (such as our partners at Scott Data) can provide an environment where you maintain full control over data and models.
Allocate more budget to team and tools than LLMs
The largest proprietary models exhibit impressive reasoning when massive documents are stuffed into prompts, but these compelling examples are not practical. Attempting to solve all problems with massive LLMs results in slow, expensive applications that won’t scale. An application that costs $3/query and takes 2 minutes to respond has poor ROI.
Build with open source LLMs and allocate your resources to talent and tools, such as frameworks, developer resources, vector databases, and LLM Ops platforms.
Stage 0: Just a Base LLM
We began by only asking the base LLM questions. Since Formula 1 is a global sport with extensive media coverage, LLMs trained on publicly-available data can answer some questions about the rules.
Figure A0: A simple question answering system without additional context
This system has an average accuracy of ~40% with significant variance by model. GPT-4 performs best at 60%, while llama2-70b only achieves 24%.
This generally poor performance is not surprising given the complex rules. The models are more likely to correctly answer questions on topics covered in the media. GPT-4 is better at answering arcane questions on topics such as Cost Cap or drag reduction system.
None of the models can reliably answer specific questions about the documents, such as “Where is the timing and documentation of scrutineering discussed in the FIA regulations?”
Stage 1: LLM + Document Search = RAG
LLMs need direct access to the rules to answer specific questions about the FIA regulations.
Since the regulations consist of several hundred thousand tokens, almost no model can accommodate the entire set in context. Providing the relevant document excerpts based on the question is a more practical solution. We use semantic search to retrieve the relevant sections and augment the LLM prompt to generate a response, hence the name retrieval augmented generations, or RAG.
For this application we use a retrieve and rerank approach to identify potentially relevant sections. The two steps are as follows:
Identify a number of potentially relevant sections by searching for texts whose embeddings have a high cosine similarity relative to the question’s embedding. The embeddings are pre-computed using an encoder-only transformer model. The model is similar to BERT but pre-trained for semantic search.
We then rerank the potentially relevant sections using a more sophisticated (and therefore slower) model that scores each sections’ relevance given the user question.
We give the top 10 results to the LLM, and it generates an answer to the user’s question. (The number 10 performed well for us, but another application could use fewer or may require more.)
.png?width=800&height=332&name=Rectangle%201626%20(1).png)
Figure A1: The RAG workflow with the regulation search (RS) function supplying relevant texts to the LLM.
The performance gain in Stage 1 is significant and surprising. Because we are providing the models with relevant document context, all models scored better with accuracies between 80% and 90%. OpenAI’s models are the best and worst performers, with GPT-4 at 89% and GPT-3.5 at 80%. Llama2-70b essentially matched GPT-4 at 88%, while mistral-7b and mixtral-8x7b scored 84% and 81% respectively.
These results lead us to the study’s most important conclusion: context retrieval is more important than model size. The dramatic increase in performance comes from providing the models with the regulations that they can turn into accurate responses.
Stage 2: Add More Context
Most failures in Stage 1 occurred because the LLM did not have the right information to generate an accurate response.
For example, when asked about driver salaries, the LLM would generally not produce an accurate response. Closer inspection revealed the cause. The FIA uses the phrase “Cost of Consideration” instead of “salary.” The LLM fails even when semantic search surfaces relevant regulations because it doesn’t know “Cost of Consideration” includes salary.
This type of failure is common in most business RAG applications because business documents have phrases with specialized meanings that differ from generic language. We solve these problems by passing definitions to the LLM as additional context. See examples here.
We modified the workflow to process user questions differently:
- Compare the user question against the set of definitions for matches.
- Look through the regulation search results for phrases in our definitions.
- Append these terms and definitions to the relevant regulations and pass them to the LLM as context.
.png?width=800&height=485&name=Rectangle%201626%20(2).png)
In Stage 2 all models achieve essentially the same performance of about 84-85%, with GPT-3.5 winning 89%. By introducing definitions we improved performance for some of the models, but we also created more consistent performance for all of them. By providing better information, the models have less need to speculate.
While the quantitative results between Stages 1 and 2 appear to be the same, closer inspection reveals practical improvements from additional context. We are strictly evaluating the accuracy of each response. In some instances a model may respond with a correct answer for spurious reasons. One particularly tricky example is, “Is there a regulation about drivers walking on or crossing a live track?” The baseline models without RAG tend to answer this question correctly: of course you shouldn’t walk on track and there must be a rule for this! When we add RAG, however, the retrieval model consistently has a hard time finding the specific regulation for this scenario, leading the LLM to conclude that there is no rule!
In practice, this additional context helps the LLM make more informed decisions instead of correctly guessing.
Stage 3: Give the Models Control
In the final Stage we gave the models the regulation and definition search functions as “tools.” The models can use these tools to run additional searches and further refine or augment their responses. These systems are often called “agents” because they can autonomously choose whether to respond or perform other actions.
Tools require complex system prompts. The LLM must generate appropriately formatted tool calls and parsers to interpret the responses. These prompts usually vary from model to model. Since OpenAI currently has this functionality built into their models and Python SDK, we only evaluated tools for the OpenAI’s models.
.png?width=800&height=501&name=Rectangle%201626%20(3).png)
Including relevant context significantly improves accuracy and levels the performance between small and large models. We saw essentially the same RAG performance between GPT-4, with an estimated 1.7 trillion parameters, and a Mistral model with only 7 billion parameters.
Figure A4 below summarizes our findings. RAG dramatically increases the response accuracy, bringing all models to over 80%. Adding additional context (definitions) helped the LLM interpret the regulations and improved performance and stability.
.png?width=800&height=500&name=image%201%20(1).png)
LLMs are general reasoning engines that distill knowledge gained from training on massive amounts of text. For business applications, however, we need to supplement this general reasoning with context-specific information through RAG.
When given the right context, small and large models perform equally well. The models do not need to perform complex reasoning or draw from general knowledge. They simply need to understand the question, read the context then generate a response.
“Context stuffing” isn’t the answer
While some observers speculate that powerful LLMs with massive amounts of context size will eliminate the need for RAG, we disagree. “Context stuffing” might be the best solution for occasional ad hoc analysis, but burdening the LLM with 99% of information it doesn’t need results in a slow, expensive, impractical solution.
Businesses will use the most cost-effective solution that gives the same results. At present that solution is small, open source LLMs powered with RAG.
Context is also the challenge for application teams
The challenge for application teams is providing the right context to an LLM. The answer is two-fold.
First, you need to understand your data. How is the text structured in the document? Are there additional sources of information, like definitions or interpretations, that need to be injected alongside the retrieved text? The garbage-in-garbage-out adage certainly holds true for RAG.
Secondly, you need a retrieval process for extracting the pertinent context given the query. The pre-trained embedding models were sufficient to achieve 80% accuracy. Further improving the retrieval by fine-tuning the embeddings (or the reranker) would lead to additional accuracy since the performance bottleneck is retrieval.